
DCGAN学习笔记

前言

学习生成方向一定绕不开的一定是在这个领域的开山之作GAN,于是跟着b站李沐老师一起读了这篇论文,醍醐灌顶。为了加深对其中数学原理的理解和加深记忆,特此记录。
这里挂上论文原文和李沐老师的视频链接
论文链接 视频链接一个关于GAN起名的有趣的背景故事
当年一作Ian在选择名字的时候,有若干个名字可以选,GAN是其中一个,有一个人告诉他说GAN在中文里面叫做干,和英文里F开头的那个词有点像,但是意义上丰富多了,然后Ian说“这个好!就它了”,因此就有了GAN这个名字。
当然这个故事也是道听途说,大家不必当真。不过GAN这个名字也很形象的描述了这个网络的特点,让我们中国人更容易理解其特点,算是一个很有趣的巧合。
接下来先用通俗的语言解释GAN网络在做的事,稍后进行理论的阐述和数学原理,然后再对DCGAN进行学习记录,和代码复现。
有监督学习和无监督学习
训练模型有两种常用的模式:有监督学习和无监督学习
有监督学习就是我们用与训练模型的数据是打好标签的。
例如分类任务中,猫图片对应的标签是”猫”,狗图片对应的标签是“狗”,然后在训练的过程中让数据通过模型后的到的预测结果与事先打好的标签做比较,反馈给模型。
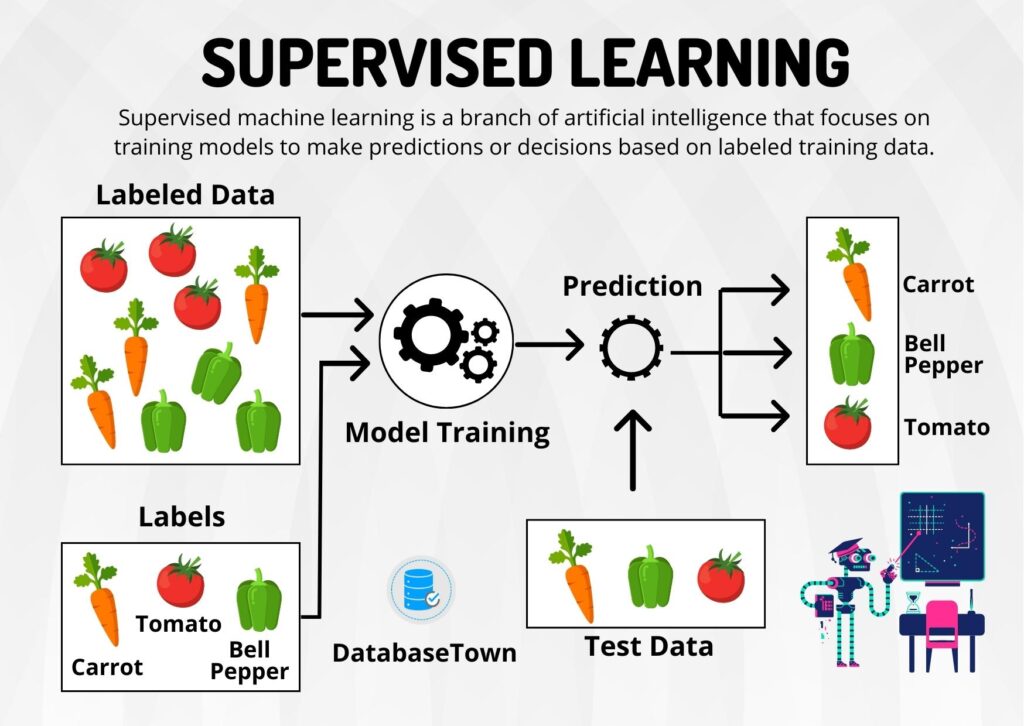
这个过程相当于人工监督模型的学习。
无监督学习的数据是不需要打标签的。
无监督学习的时候没有明确的目标,也因此难以量化其效果。
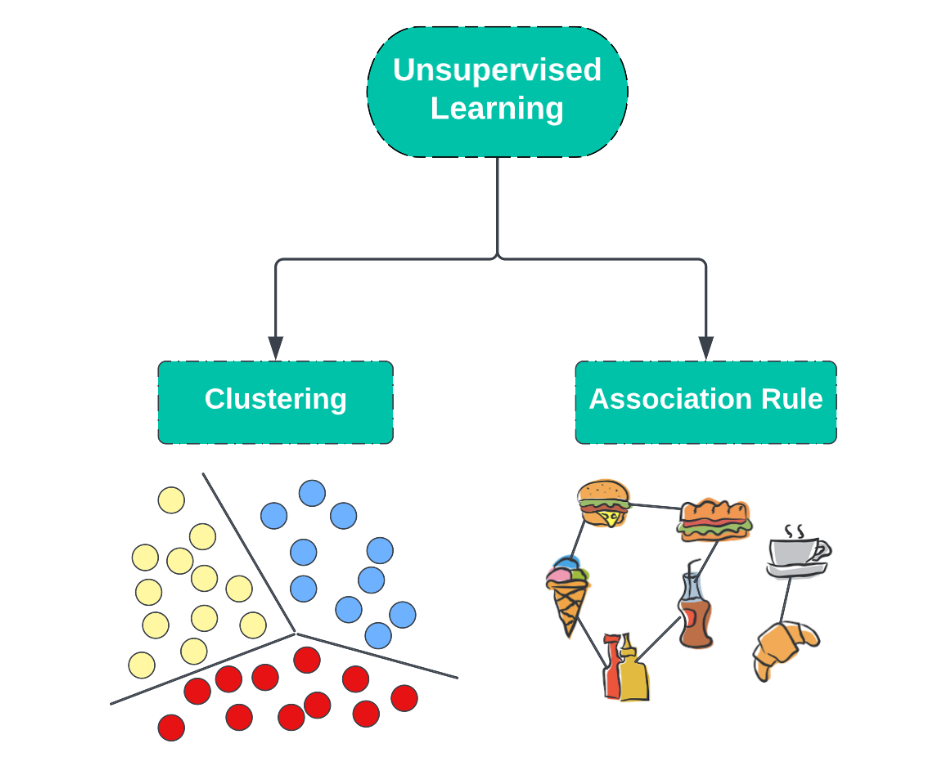
这里举一个常见的例子:
“聚类”算法
我们把数据扔给模型,模型会自动根据数据的分布把数据分为几个类别,收敛到一定程度之后会呈现几个类别,这时候作为人类并不知道这几个类别具体代表了什么,然后再去研究这些类别的特征。
最典型的聚类算法是K均值聚类算法。
GAN属于无监督学习,因为我们在训练模型的时候并不需要给数据打标签,我们也无法打标签,因为是生成,生成的效果是很难量化表示的,目标是很难明确的。
GAN在做什么?
GAN的全称叫做生成对抗网络(Generative Adversarial Nets)。生成很好理解,这个网络的目的是实现生成;对抗,也是这个网络的精髓所在,也是为什么说“干”很能体现其精髓。
这里对其原理进行一个通俗的阐述:
首先我们需要提供的是随机噪音z和样例图片集Real images
为了达到生成的目的,我们需要一个生成器(Generator),这个模块负责完成生成。给定生成器一个随机噪声z,生成器会根据它生成一个分布,我们称其为Fake images
为了让这个生成器更加优秀,我们需要一个判别器(Discriminator),这个模块相当于分类任务中的分类器,是一个二分类的分类器。这个分类器的任务是区分开Real images和Fake images
所以训练过程可以看作生成器和判别器之间的对抗
- 判别器的目的是尽可能的区分生成器生成的fake image和给定的real image之间的区别。
- 生成器的目的是尽可能的混淆判别器,让它无法区分自己生成的图片和真实图片
就好比生成器是造假钞的团伙,判别器是查假钞的警察。警察的目的是尽可能地区分假钞和真钞;假钞团伙的目的是尽可能地造出更接近真钞的假钞混淆警察。
训练的过程就是两个模型螺旋上升的过程。
初始,判别器判别的能力很差,生成器生成的能力很差。
首先我们用生成器生成一张图片,然后对判别器进行若干轮的训练,些微提升它的判别能力
然后对生成器进行训练,逐渐让判别器分类的结果趋近于0.5(即无法区分)
然后循环往复,若干轮以后生成器生成的图片就会逼真。
对抗网络的数学表达
我们的目的是根据数据
我们训练
的目的是最大限度提高G中的训练样本和真实样本被区分出来的概率。也就是希望 是真实数据的时候 越接近1; 是G给出的输出的时候, 越接近0。 训练G的目的是让
尽可能小,也就是希望 尽可能接近1,也就是G生成的数据尽可能使判别器混淆。
因此可以定义价值函数函数
这个对抗网络的目的就是
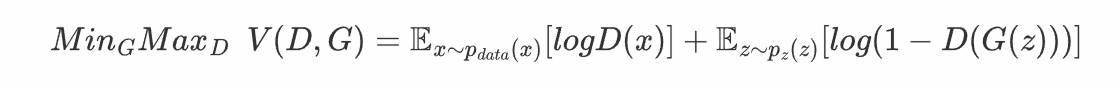
通过上述解释,这个式子是较好理解的,其中前项表示
DCGAN
DCGAN是继GAN之后比较好的改进,其主要的改进主要是再网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大地提升了GAN训练的稳定性以及生成结果质量。
它首先由Radford等人在论文《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS》中提出
论文链接DCGAN网络设计中采用了当时CNN比较流行的方案
- 将空间池化层用卷积层替代,这种替代只需要将卷积的步长stride设置为大于1的数值。改进的意义是下采样过程不再是固定的抛弃某些位置的像素值,而是可以让网络自己去学习下采样方式。
- 将全连接层去除。作者通过实验发现了全局均值池化有助于模型的稳定性但是降低了模型的收敛速度;作者在这里说明了他是通过将生成器输入的噪声reshape成4D的张量,来实现不用全连接而是用卷积的。
- 采用BN层,BN的全称是Batch Normalization,是一种用于常用于卷积层后面的归一化方法,起到帮助网络的收敛等作用。
具体细节
- 使用指定步长的卷积层代替池化层
- 生成器和判别器中都使用BN
- 移除全连接层
- 生成器除去输出层采用Tanh外,全部使用ReLU作为激活函数
- 判别器所有层都使用LeakyReLU作为激活函数
几个重要的概念
在理解DCGAN之前需要理解几个重要的概念
上采样(subsampled)
下采样实际上就是缩小图像,主要目的是为了使得图像符合显示区域的大小,生成对应图像的缩略图。比如说在CNN中得池化层或卷积层就是下采样。不过卷积过程导致的图像变小是为了提取特征,而池化下采样是为了降低特征的维度。
下采样(upsampling)
有下采样也就必然有上采样,上采样实际上就是放大图像,指的是任何可以让图像变成更高分辨率的技术,这个时候我们也就能理解为什么在GG网络中能够由噪声生成一张图片了。
它有反卷积(Deconvolution)、上池化(UnPooling)方法。这里我们只介绍反卷积,因为这是是我们需要用到的。
卷积和反卷积(Deconvolusion)
卷积操作是一种在信号处理和图像处理中广泛应用的数学运算,尤其在深度学习领域中的卷积神经网络(CNNs)里非常关键。它通过一个称为“卷积核”或“滤波器”的小矩阵与输入数据进行滑动点乘加运算,来实现对数据特征的提取。卷积操作通常是降采样的过程,即它减少了图像的空间维度,同时增加了通道数(如果使用多个卷积核),在这个过程中,提取出越来越多的特征(李沐的课程中提到过,可以认为每个像素拥有一个长为通道数的向量作为特征)
卷积操作的运算公式是
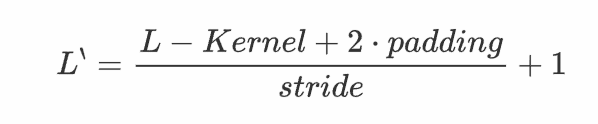
反卷积(Deconvolution)也称为分数步长的卷积和转置卷积(transposed convolution)。在下图中,左边的为卷积,右边的为反卷积。convolution过程是将4×4的图像映射为2×2的图像,而反卷积过程则是将2×2的图像映射为4×4的图像,两者的kernel size均为3。不过显而易见,反卷积只能恢复图片的尺寸大小,而不能准确的恢复图片的像素值。
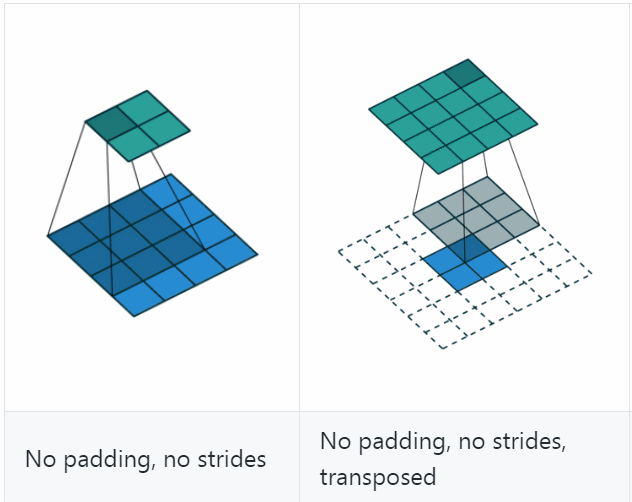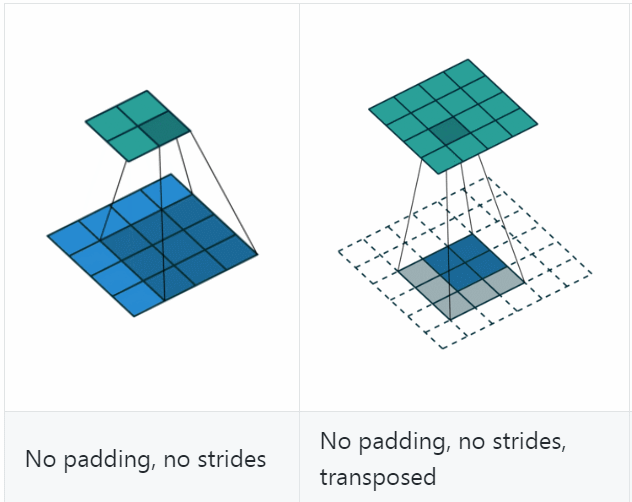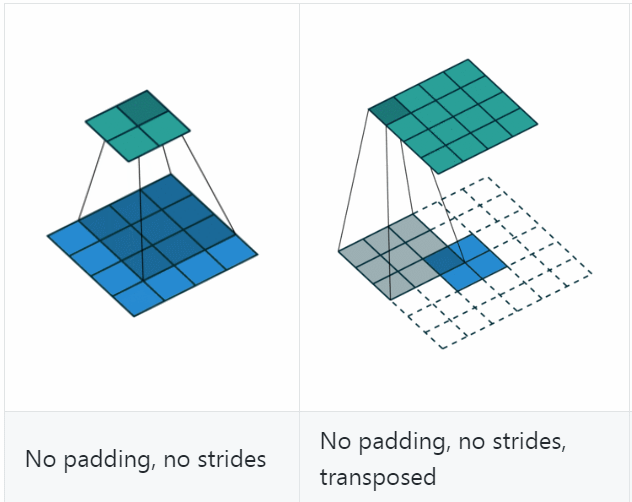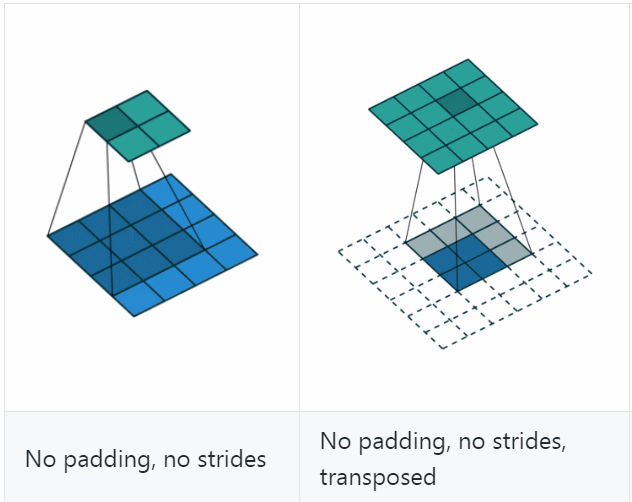
反卷积和卷积一样,搭配不同的步长、填充,会有不同的效果
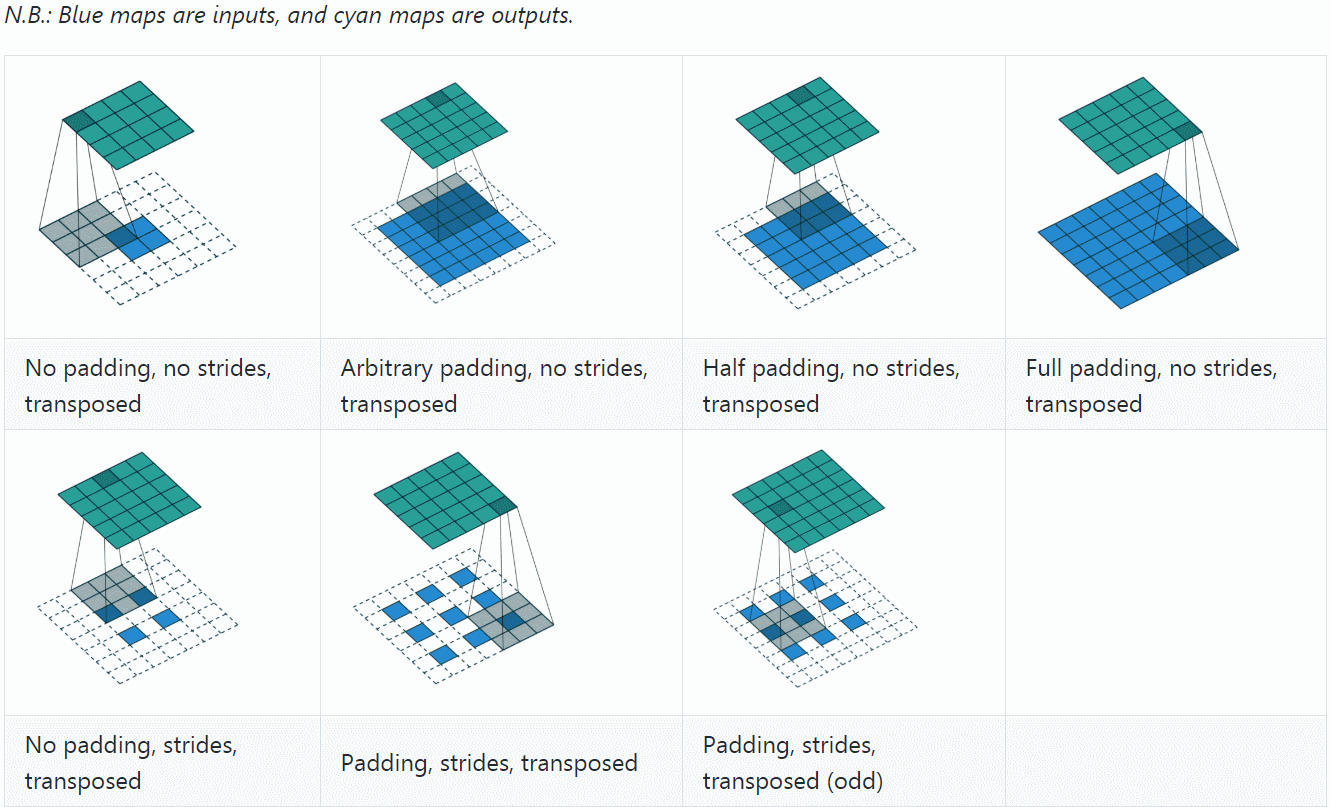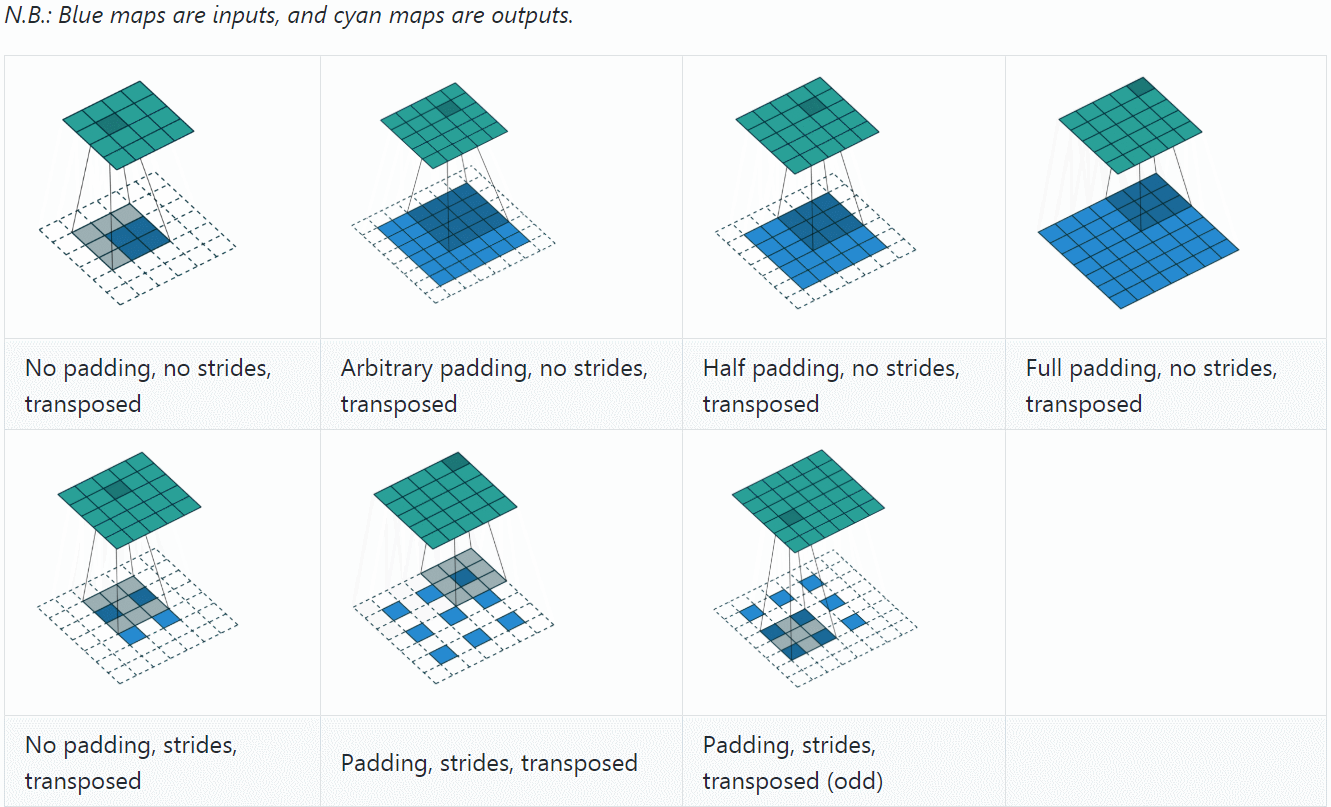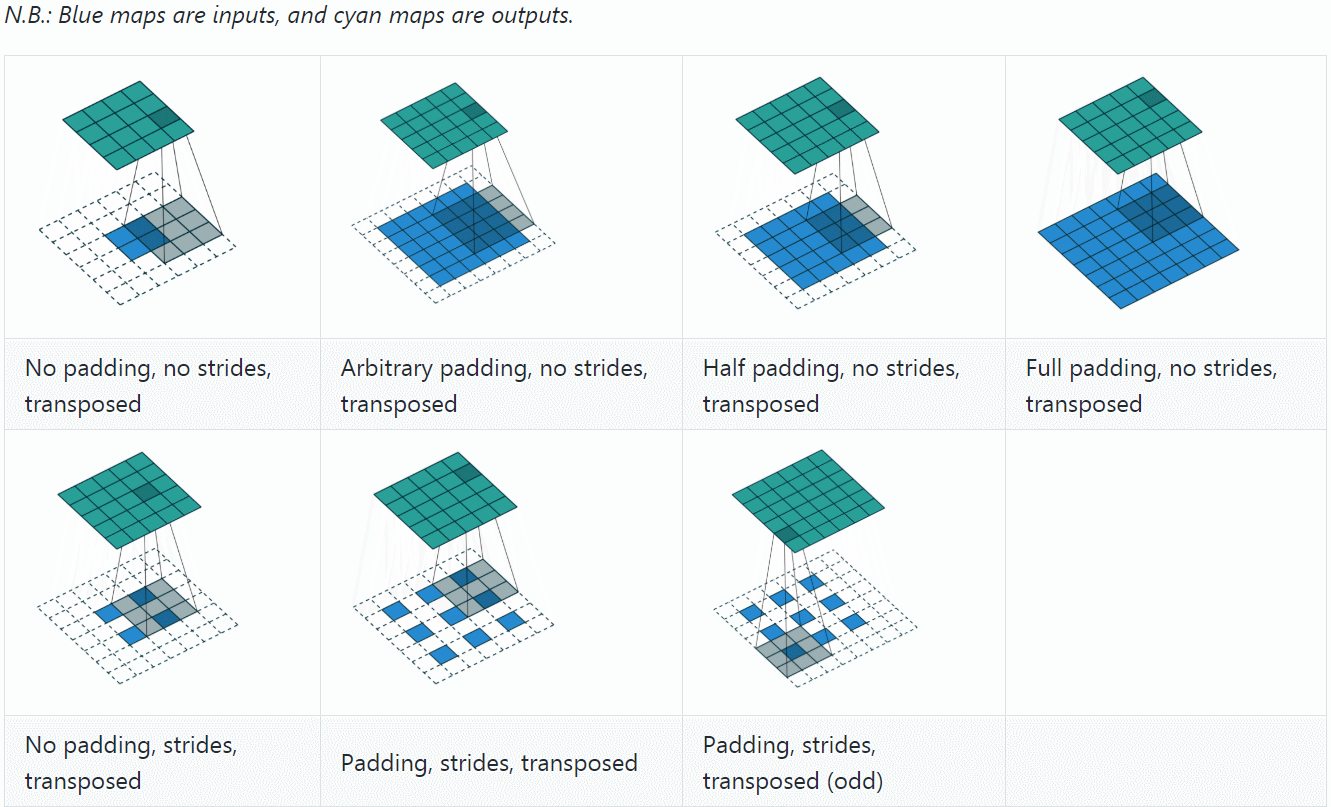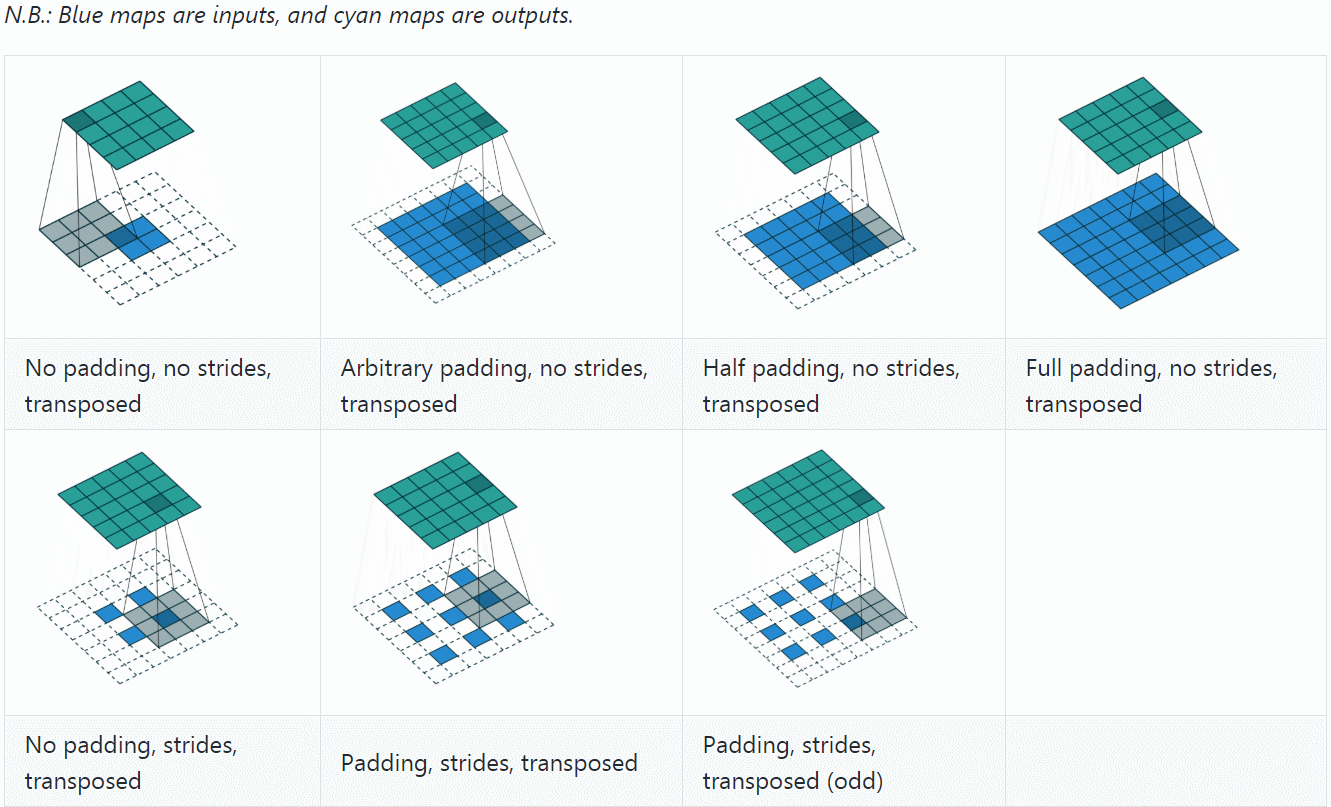
可以看到,反卷积的padding是减少本应有的padding,会让生成的图片变小;stride表现在在原图片中加入分隔的空,可以理解为分数步长。
计算公式是(可以把它stride和padding做完后就当作是卷积操作,然后先计算卷积之前图的大小,然后套卷积的公式即可)、
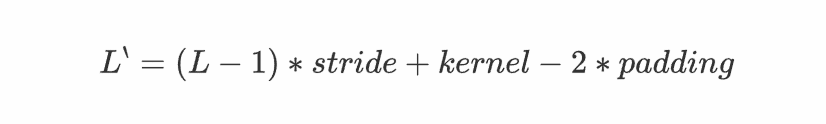
批量归一化(Batch Normalization)
对于一个很深的网络,在backward的时候,往往顶部的梯度比较大,变化速度快;但是底部的梯度小,变化速度慢;底部发生一点变化的时候,顶部都会跟着变化。因此就会出现随着底部的不断训练,顶部不断地快速地训练了很多次,降低了训练地效率。所以我们希望训练地过程中顶部随着底部变化的程度小一点,加速收敛。
批量归一化在做的就是把上一层输出的数据分布固定到我们规定的数据分布中,使得下一层在接受数据的时候数据分布不会变化太大,这样就很好的解决了前层的变化带动后层频繁变化的问题。
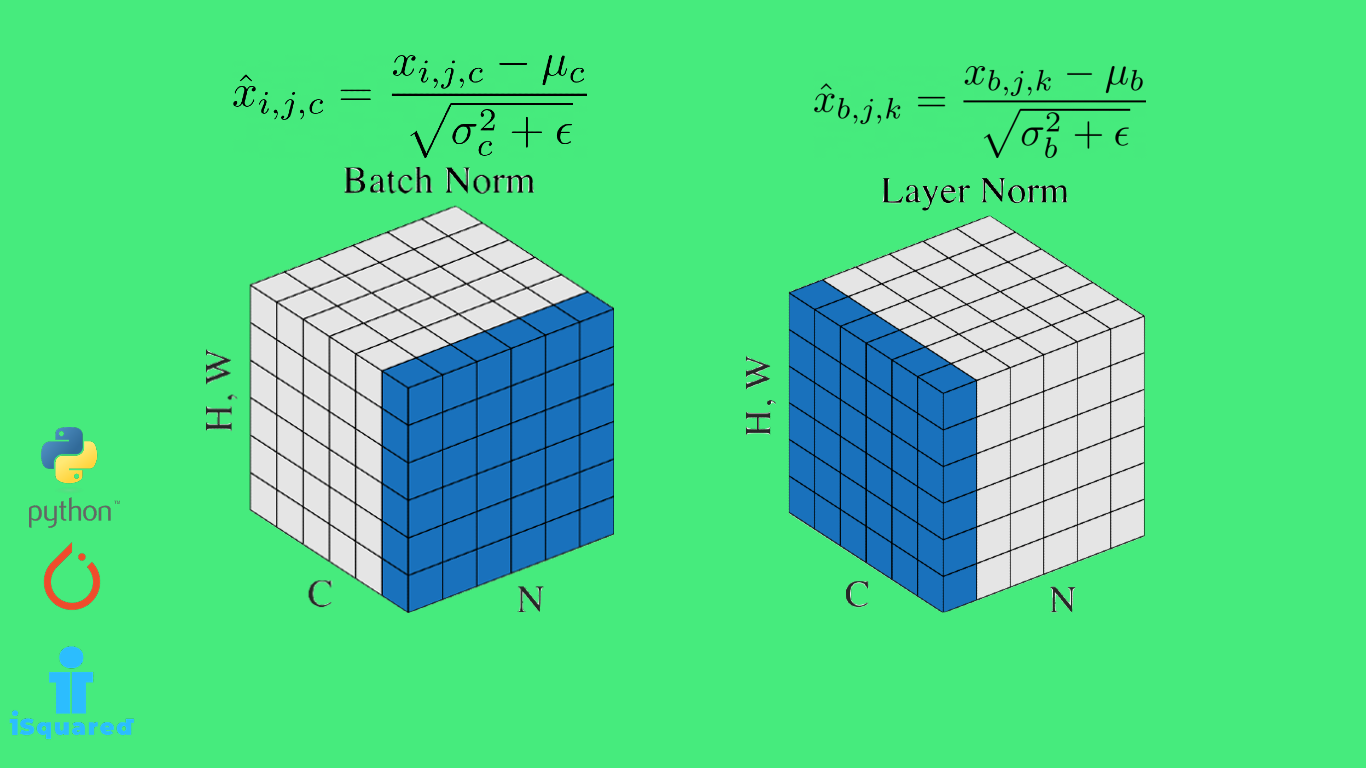
一开始无法理解的原因是我无法理解数据流在层与层之间被改动了信息就会丢失或者被篡改。后来让我茅塞顿开的是理解了神经网络层与层之间提取的特征是不重叠的,(例如第一层提取到的是轮廓信息、第二层提取到的是纹理信息),那么它们感兴趣的数据尺度很可能是不同的,(例如第一层对(-5,5)的数据敏感、第二层对(-100,100)的数据敏感),这时候如果没有BN层在中间的话,第二层需要跟着第一层的变化而不断适应它的尺度,因此这时候加入BN层,相当于在两个层中做到了“隔离”“缓冲”的作用,使得后面的网络对前面的数据分布变化不这么敏感了,只需要在提取过信息的数据中再提取自己需要的信息即可。
这里举个例子加深理解:还是以第一层提取轮廓信息,第二层提取纹理信息为例。在训练的过程中,由于第一层提取的是轮廓信息,不论其输出的分布怎么变化,都是提取过轮廓信息以后的,纹理信息是没有被提取的,那么BN层对其进行归一化,归一到一个符合第二层敏感的分布上,并不会改变其本身的纹理信息,所以正确性不会受影响的同时,效率和准确性也会提高。
具体使用
Batch Norm的最初想法其实是在层与层之间对数据进行白化,从这个角度也是很好理解的。因此其公式就是
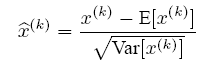
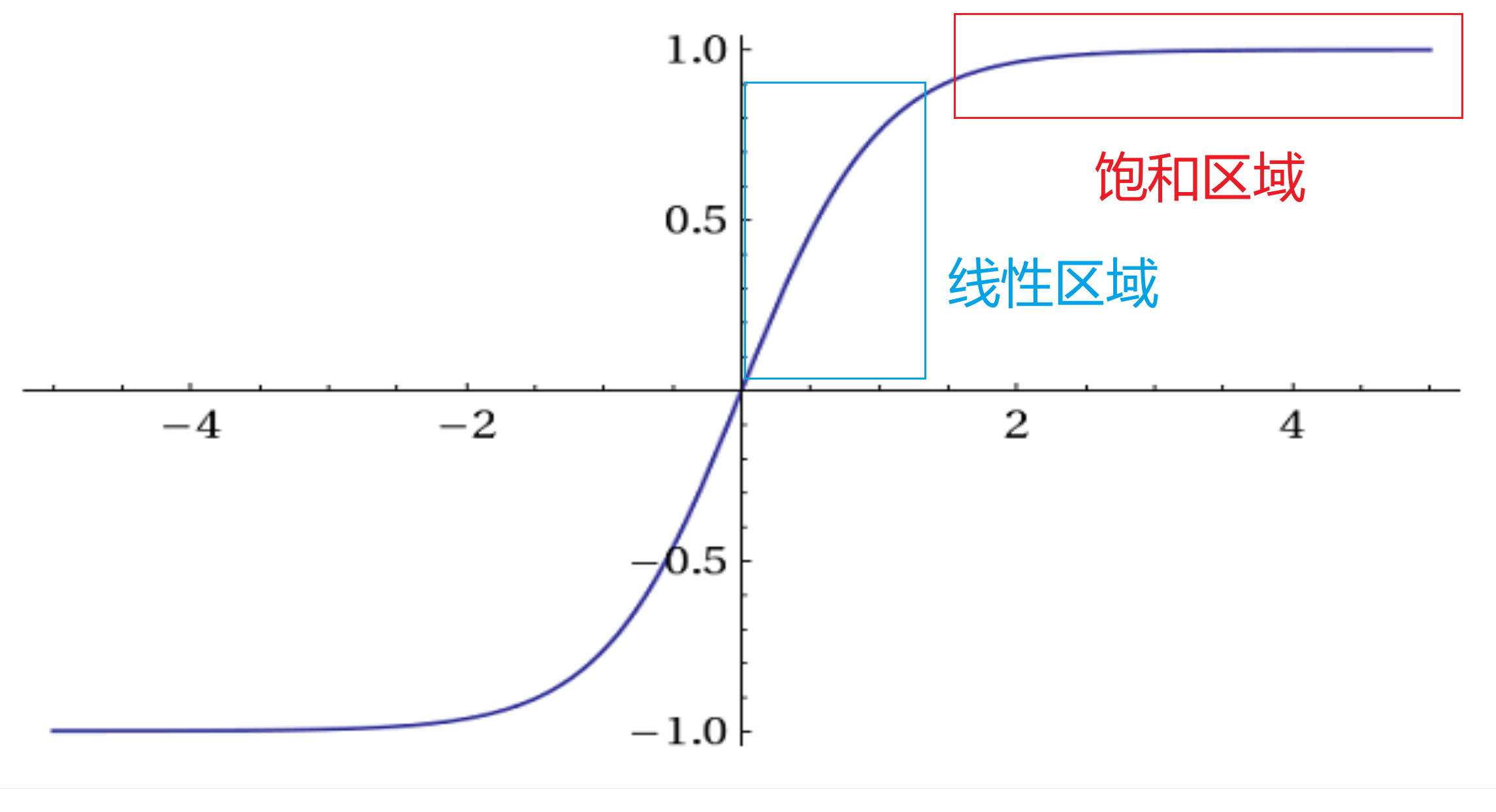
本身多层感知机的非线性性是靠激活函数对不同的层进行分隔实现的,例如Sigmoid,Tanh,他们呢都有一个“饱和区域”,在这些区域里函数非常平缓,几乎接近直线,在这些饱和区域,梯度会变得非常小,这就会导致梯度消失的问题。BN的其中一个作用就是把数据从“饱和区域”拉回到激活函数的线性响应区域,这样激活函数对输入的变化更加敏感,梯度也更大,从而有助于解决梯度消失问题,加快学习速度。
但是这样会出现一个问题,如果仅仅是对数据进行白化,那么相当于基本把所有数据都拉向线性区,这样激活函数的作用就不大了,使得模型趋于线性,模型的表达能力就变差。
因此在此基础上加入了scale和shift的反变换操作
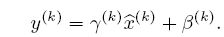
因此BN层的操作流程就是

但是推理过程中,没有mini-batch,所以BN层做的是把每个mini-batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局的统计量
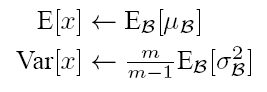
然后的流程就是相同的了。
模型结构
Generator
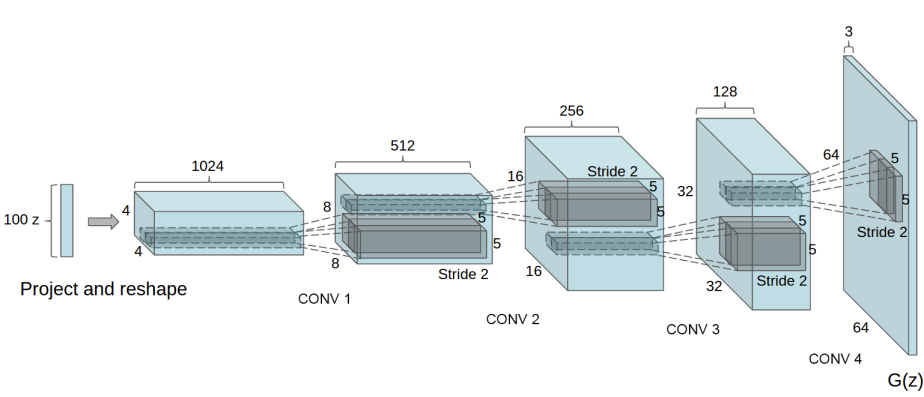
1 | class G(nn.Module): |
Discriminator
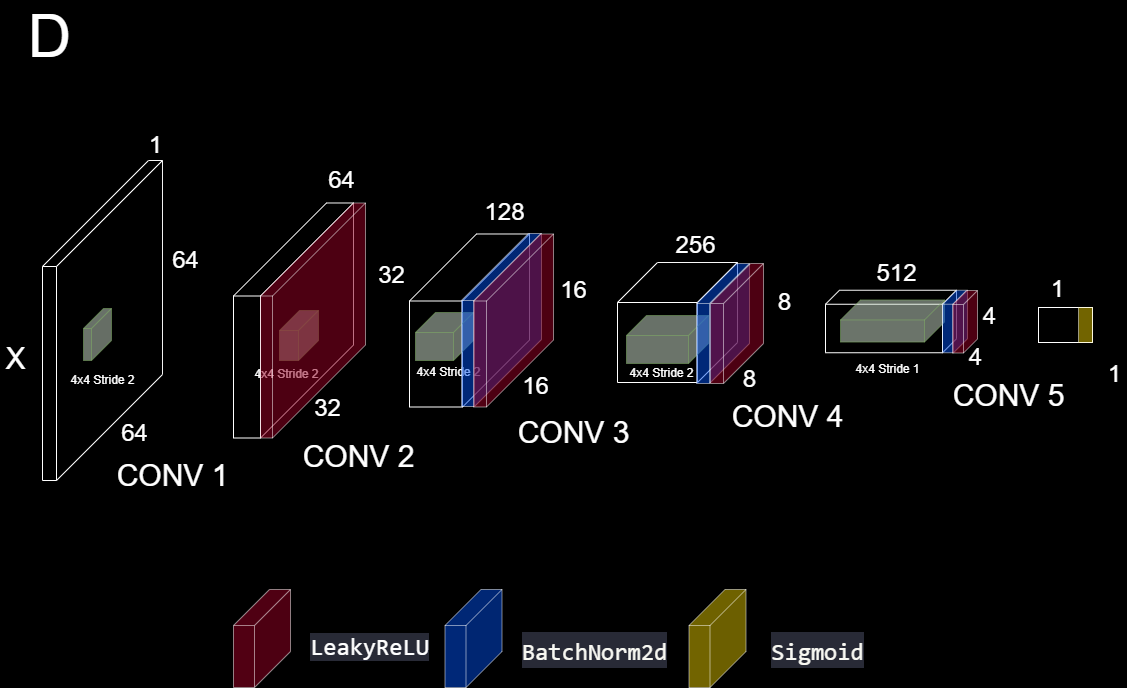
1 | class D(nn.Module): |
Lightning模块
1 | class AutoNet(lightning.LightningModule): |
输入数据预览

训练
1 | from models.Generator import G |
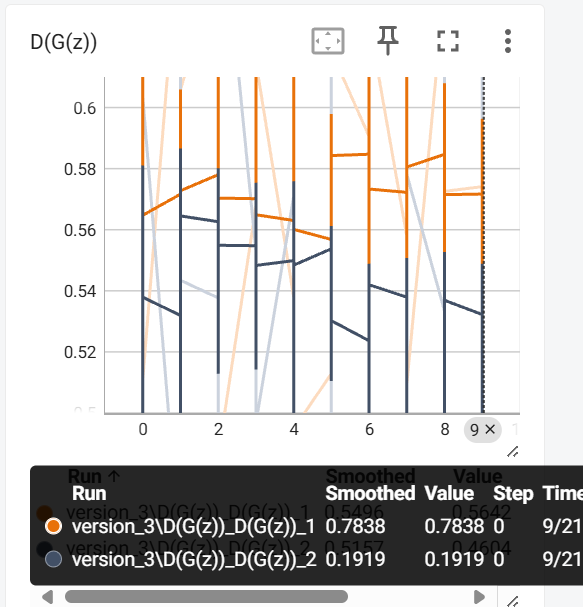
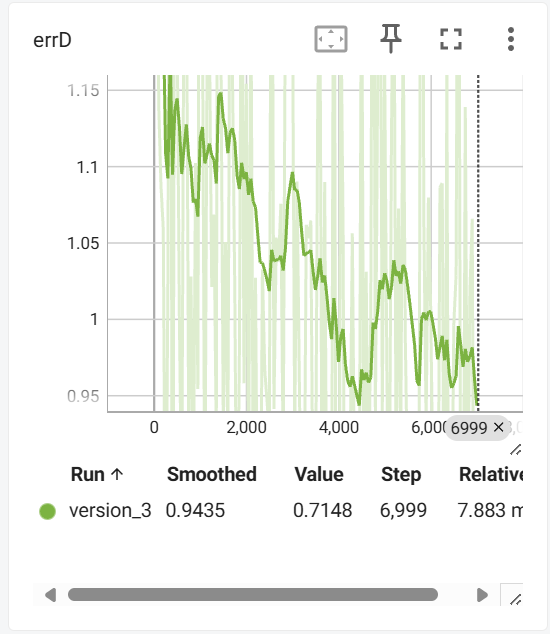
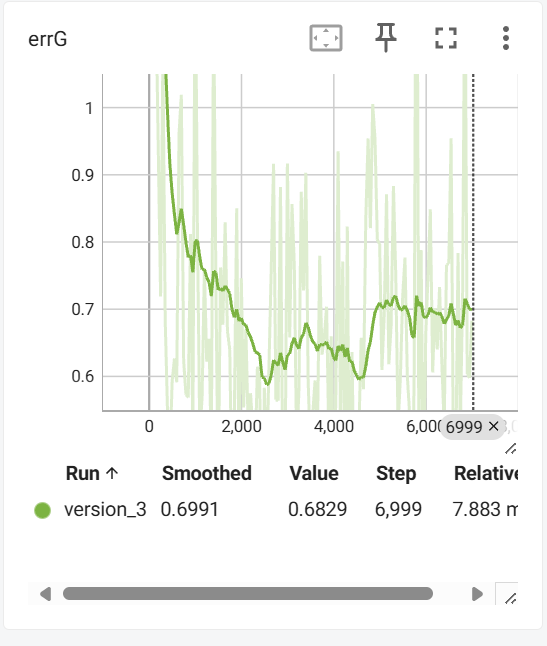
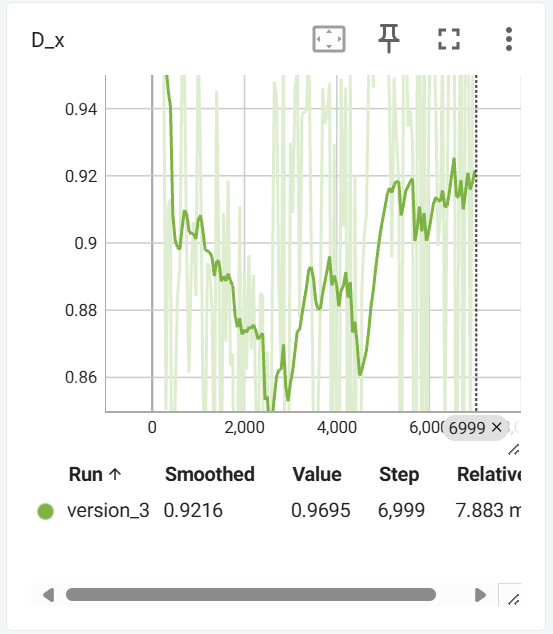
预测结果

- Title: DCGAN学习笔记
- Author: Chandery
- Created at : 2024-09-13 11:31:28
- Updated at : 2024-12-11 10:43:51
- Link: https://chandery.chat/2024/09/13/DCGAN学习笔记/
- License: This work is licensed under CC BY-NC-SA 4.0.